Proven on real retrieval benchmarks
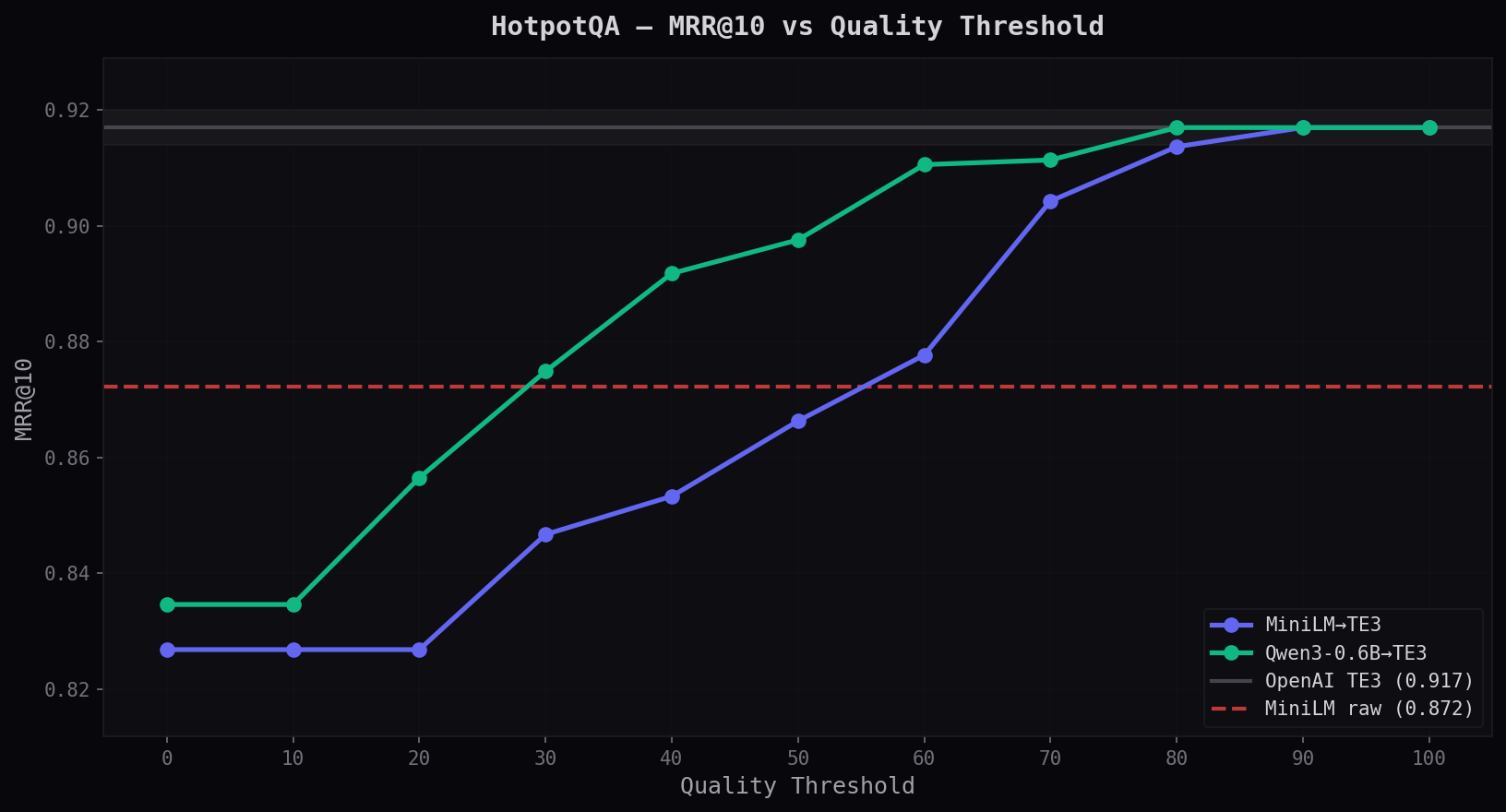
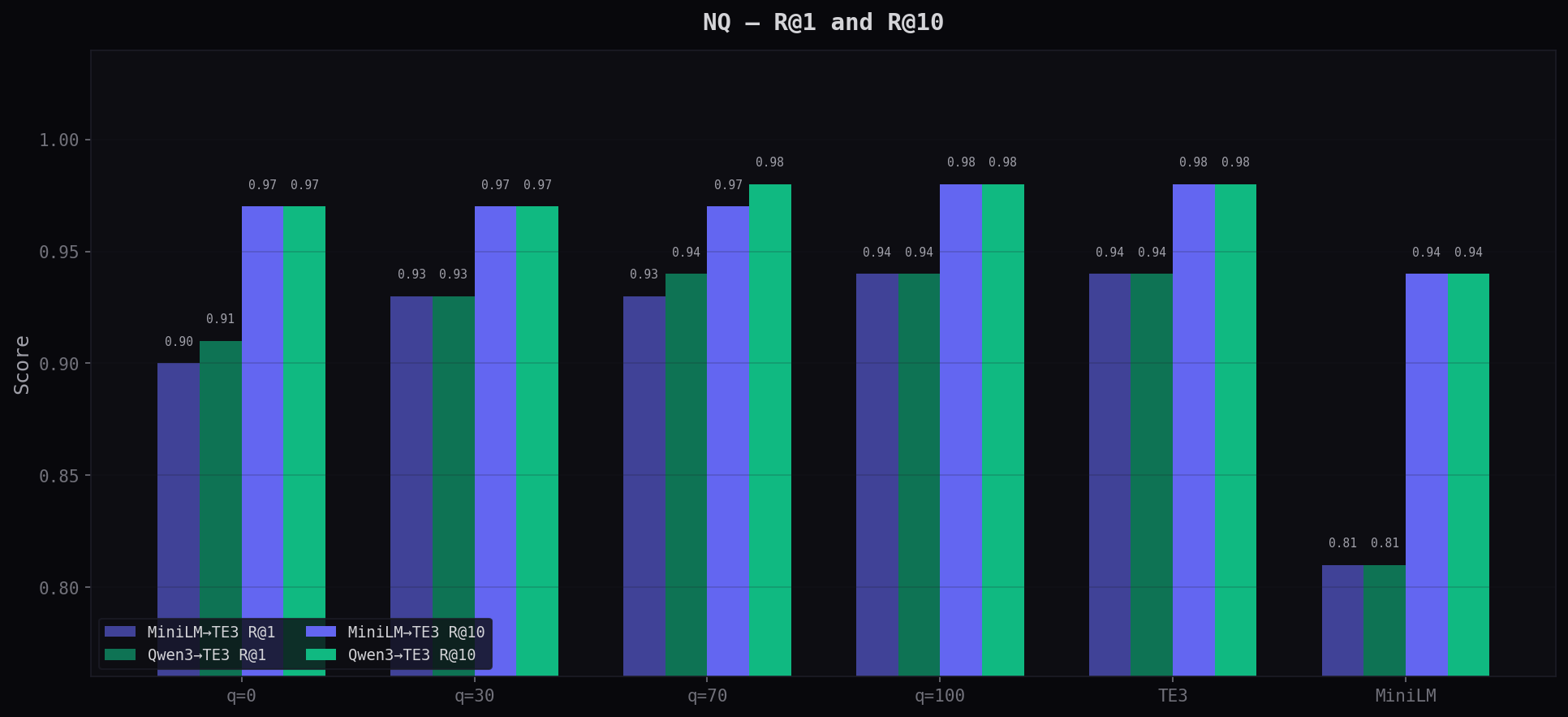
Tested on HotpotQA (multi-hop reasoning) and Natural Questions (factoid Q&A). Adapted queries search a corpus embedded with OpenAI text-embedding-3-large — the same setup you'd use in production.
Query across embedding spaces
Universal embedding-space translation library. Plug-and-play adapters that map one model's vector space into another — locally, instantly, for free. Learn more →
Same ranking as OpenAI. 69% cheaper. See how the adapter compares to the raw model below.
Tested on HotpotQA (multi-hop reasoning) and Natural Questions (factoid Q&A). Adapted queries search a corpus embedded with OpenAI text-embedding-3-large — the same setup you'd use in production.
18,000 tokens/second on a single GPU. Process your entire corpus locally without waiting on API rate limits or paying per-token.
Every text gets a quality score. High-confidence embeddings stay local. Low-confidence ones route to the provider. You control the threshold per-request.
Base adapters not perfect for your domain? Create a custom LoRA that learns from provider fallbacks. Accuracy improves over time, routing costs drop.
Run provider-grade embeddings locally at 18,000 tok/s. Smart routing handles the edge cases. Your index stays exactly the same.